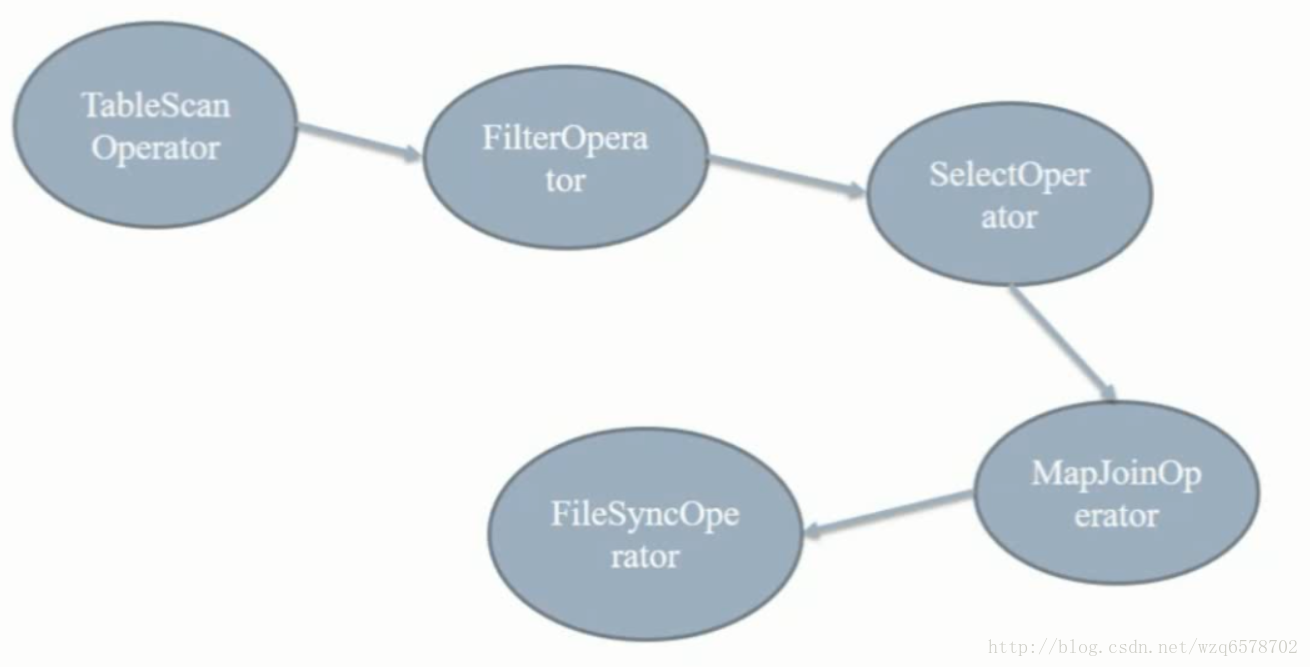
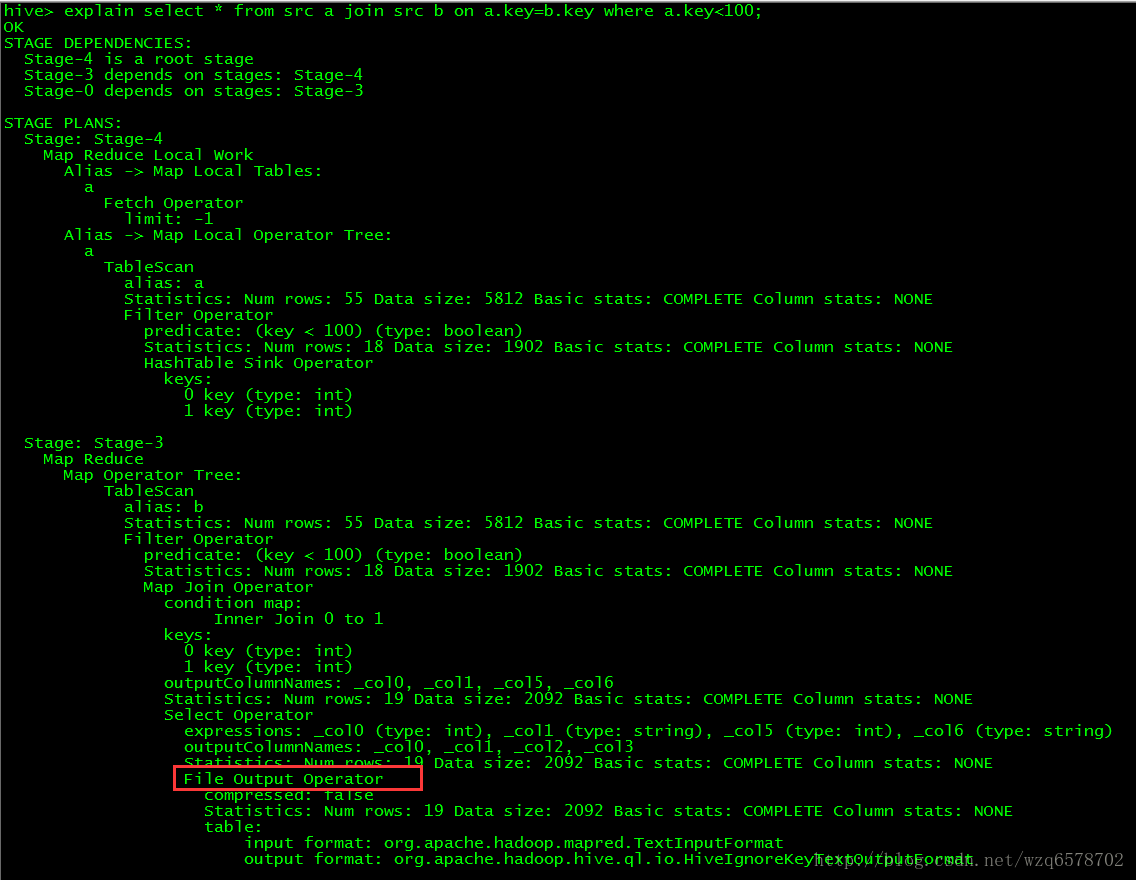
hive> explain select * from src a join src b on a.key=b.key where a.key<100; OK STAGE DEPENDENCIES: Stage-4 is a root stage Stage-3 depends on stages: Stage-4 Stage-0 depends on stages: Stage-3
STAGE PLANS: Stage: Stage-4 Map Reduce Local Work Alias -> Map Local Tables: a Fetch Operator limit: -1 Alias -> Map Local Operator Tree: a TableScan alias: a Statistics: Num rows: 55 Data size: 5812 Basic stats: COMPLETE Column stats: NONE Filter Operator predicate: (key < 100) (type: boolean) Statistics: Num rows: 18 Data size: 1902 Basic stats: COMPLETE Column stats: NONE HashTable Sink Operator keys: 0 key (type: int) 1 key (type: int)
Stage: Stage-3 Map Reduce Map Operator Tree: TableScan alias: b Statistics: Num rows: 55 Data size: 5812 Basic stats: COMPLETE Column stats: NONE Filter Operator predicate: (key < 100) (type: boolean) Statistics: Num rows: 18 Data size: 1902 Basic stats: COMPLETE Column stats: NONE Map Join Operator condition map: Inner Join 0 to 1 keys: 0 key (type: int) 1 key (type: int) outputColumnNames: _col0, _col1, _col5, _col6 Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: _col0 (type: int), _col1 (type: string), _col5 (type: int), _col6 (type: string) outputColumnNames: _col0, _col1, _col2, _col3 Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE File Output Operator compressed: false Statistics: Num rows: 19 Data size: 2092 Basic stats: COMPLETE Column stats: NONE table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Local Work: Map Reduce Local Work
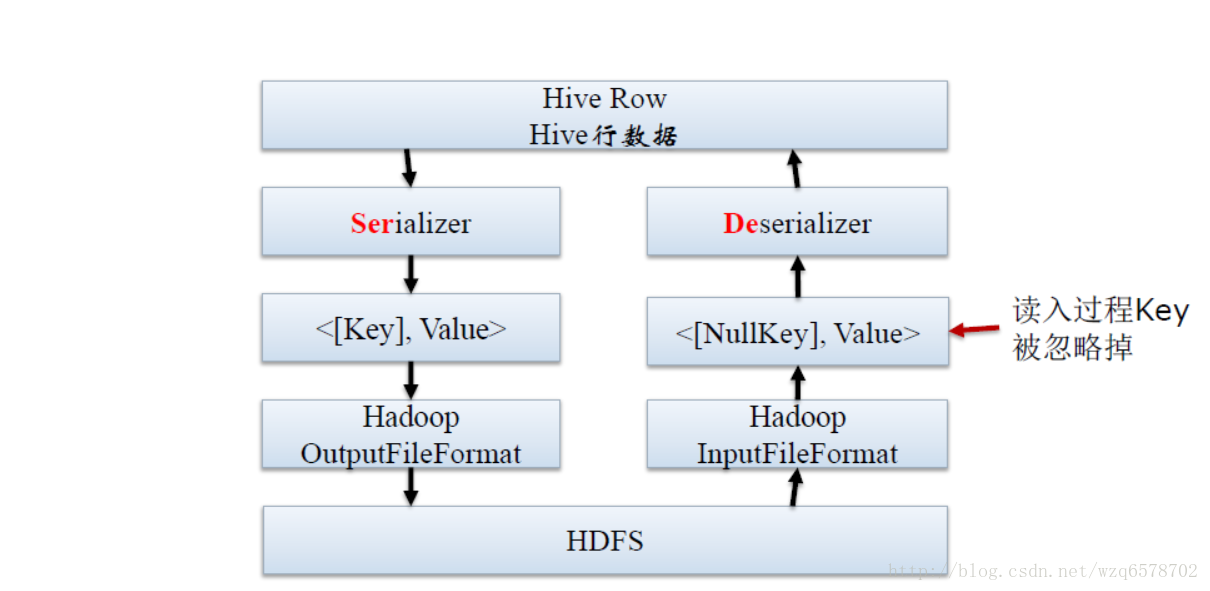
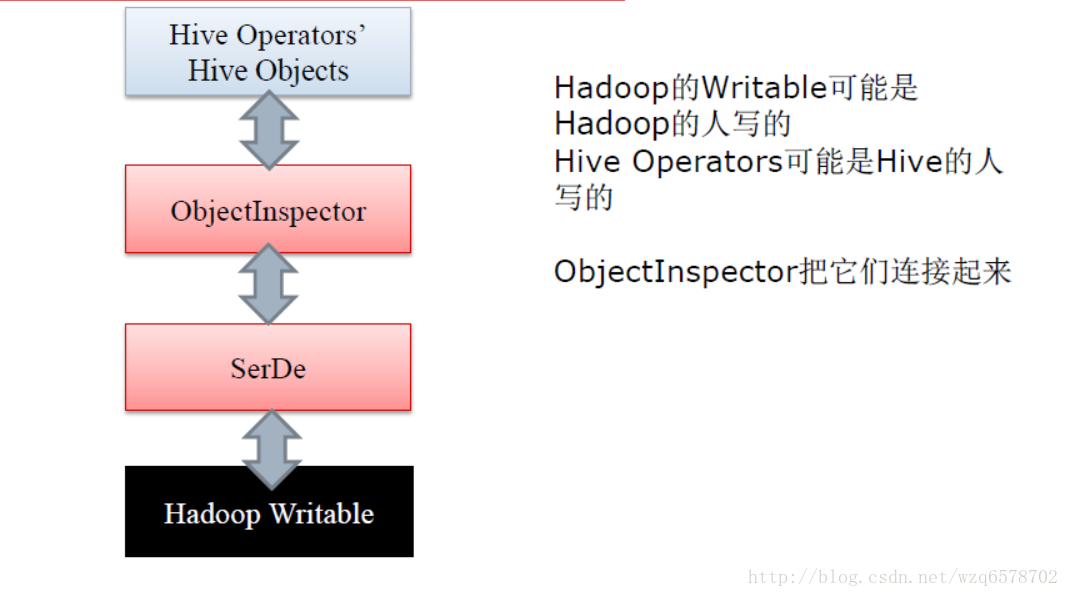
/** * Abstract class for implementing SerDe. The abstract class has been created, so that * new methods can be added in the underlying interface, SerDe, and only implementations * that need those methods overwrite it. */ public abstract class AbstractSerDe implements Deserializer, Serializer { 。。。。。。。。。。略 /** * Initialize the HiveSerializer. * @param conf System properties. Can be null in compile time * @param tbl table properties * @throws SerDeException */ //初始化 @Deprecated public abstract void initialize(@Nullable Configuration conf, Properties tbl) throws SerDeException; 。。。。。。略 /** * Serialize an object by navigating inside the Object with the * ObjectInspector. In most cases, the return value of this function will be * constant since the function will reuse the Writable object. If the client * wants to keep a copy of the Writable, the client needs to clone the * returned value. */ //序列化操作,参数obj是hive中的对象,Writable 是hadoop中的数据格式描述抽象 public abstract Writable serialize(Object obj, ObjectInspector objInspector) throws SerDeException;
。。。。。。。。。。略 /** * Deserialize an object out of a Writable blob. In most cases, the return * value of this function will be constant since the function will reuse the * returned object. If the client wants to keep a copy of the object, the * client needs to clone the returned value by calling * ObjectInspectorUtils.getStandardObject(). * * @param blob The Writable object containing a serialized object * @return A Java object representing the contents in the blob. */ //反序列化 blob是hadoop中的数据抽象格式,返回的是Object是hive中的对象 public abstract Object deserialize(Writable blob) throws SerDeException; ..........略。。。。。。。
public static final String FIELD_DELIM = "field.delim";//字段域分隔符 public static final String COLLECTION_DELIM = "colelction.delim";//集合内部元素之间分隔符 public static final String MAPKEY_DELIM = "mapkey.delim";//map的key和value之间的分割符
我们在上文的 explain select * from src a join src b on a.key=b.key where a.key<100;执行计划的时候,在stage-3有一个 Map Operator,这个操作是一个读操作,即反序列化Deserializer。 Deserializer是如何工作的 https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/exec/MapOperator.java?line=125 value : hadoop中一条数据;context:hadoop的配置