hive原理与源码分析-物理执行计划与执行引擎(六)
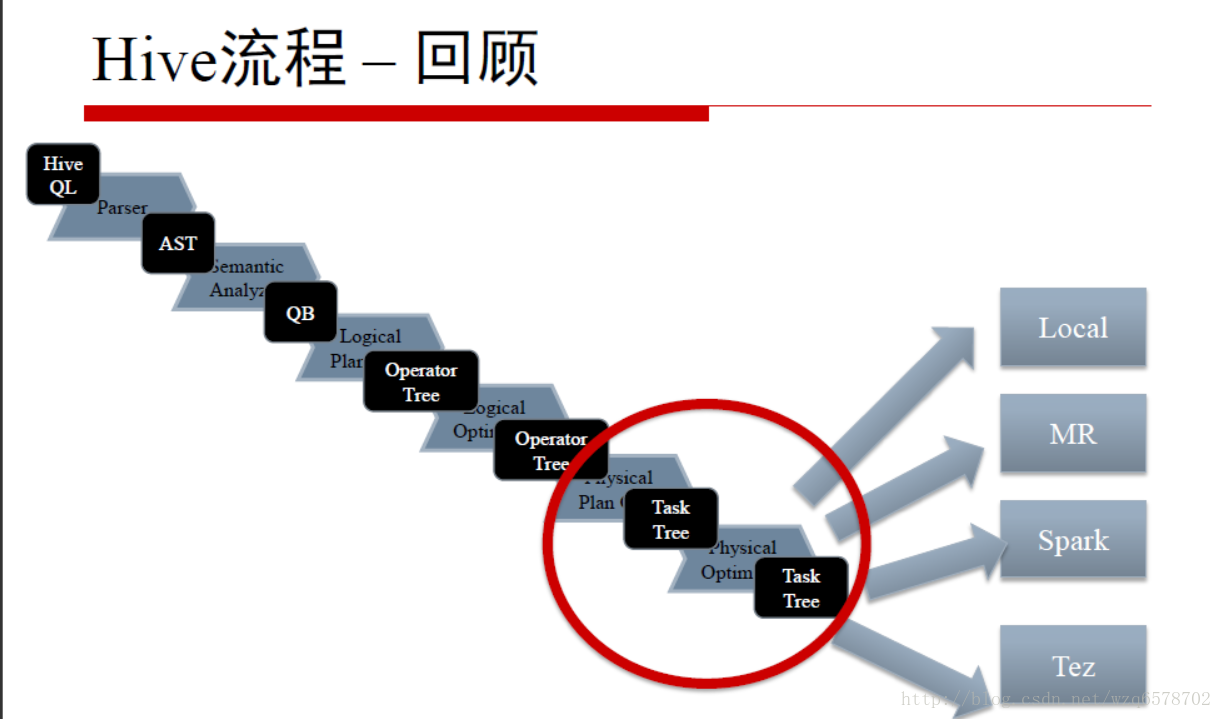
Hive执行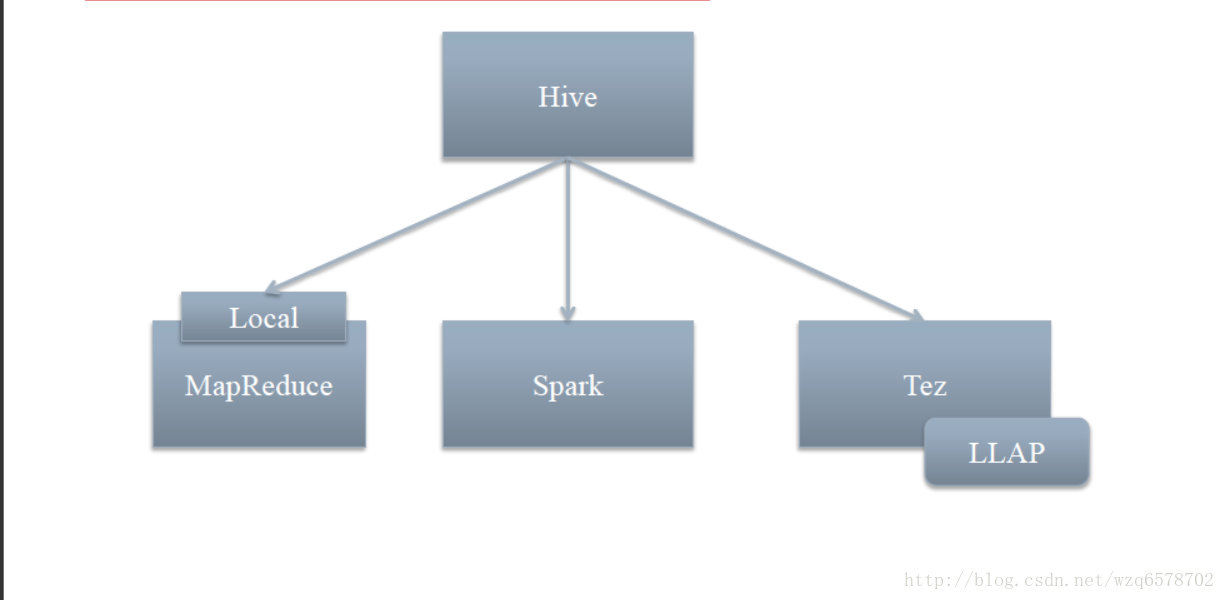
相关配置
hive.execution.engine - Hive执行引擎
mr - 在MapReduce上执行
tez - 在Tez上执行
spark - 在Spark上执行
hive.execution.mode – Hive执行模式
container - 在Yarn Container内执行Query Fragments
llap – 在LLAP内执行Query Fragments
https://insight.io/github.com/apache/hive/blob/master/common/src/java/org/apache/hadoop/hive/conf/HiveConf.java?line=2635
物理执行计划和逻辑执行计划的区别
逻辑执行计划是一个Operator图
物理执行计划是一个Task图
物理执行计划是把逻辑执行计划切分成子图
物理执行计划图的每个Task结点内是一个Operator结点的子图
举个例子
SELECT * FROM a JOIN b ON a.id=b.id;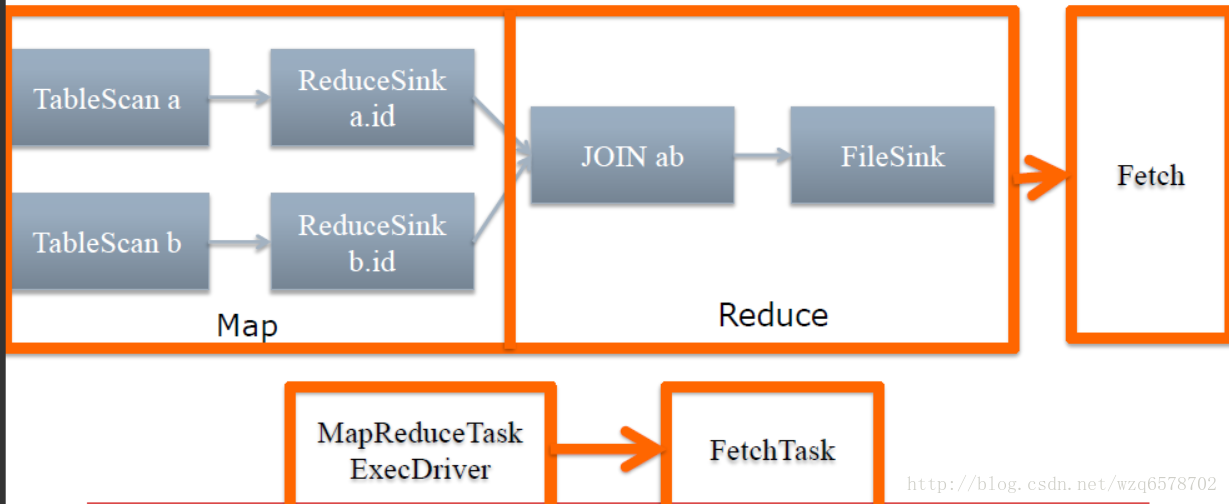
物理执行计划的Task类型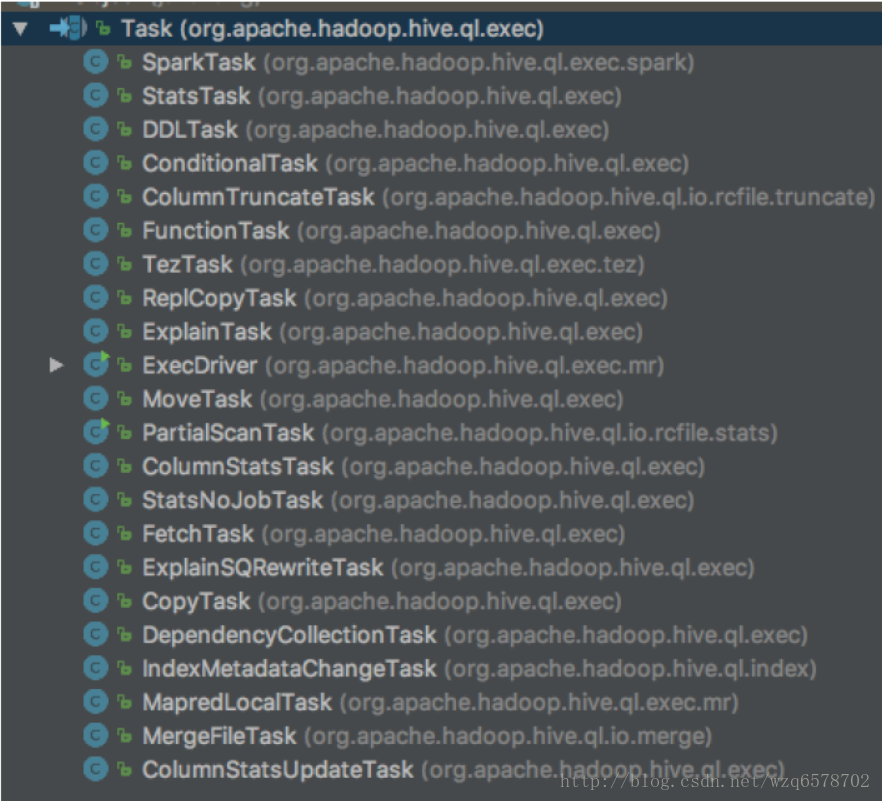
逻辑层和物理层的分界
逻辑优化的最后一步
Optimizer的最后一步
SimpleFetchOptimzer
看代码
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/Optimizer.java?line=228
1 | if (!HiveConf.getVar(hiveConf, HiveConf.ConfVars.HIVEFETCHTASKCONVERSION).equals("none")) { |
SemanticAnalyzer第七步
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/SemanticAnalyzer.java?line=11356
1 | if (LOG.isDebugEnabled()) { |
开始搞物理执行计划
TaskCompilerFactory是编译器的工厂类
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/TaskCompilerFactory.java?line=38
1 | /** |
支持tez、spark、和mr方式。
途中rootTask就是生成的有向无环图的指针。
TaskCompiler
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/TaskCompiler.java?line=87
1 | //生成物理执行计划 |
TaskCompiler.generateTaskTree()
MapReduceCompler.generateTaskTree()
SparkCompler.generateTaskTree()
TezCompler.generateTaskTree()
不同的引擎有不同的物理优化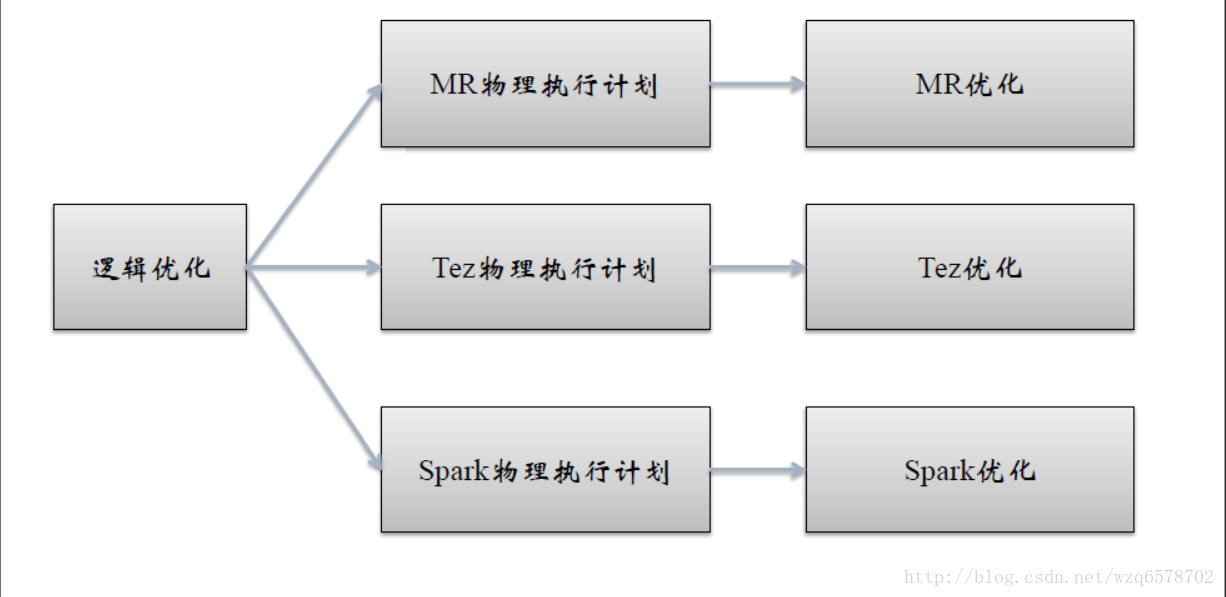
MapReduceCompiler 生成物理执行计划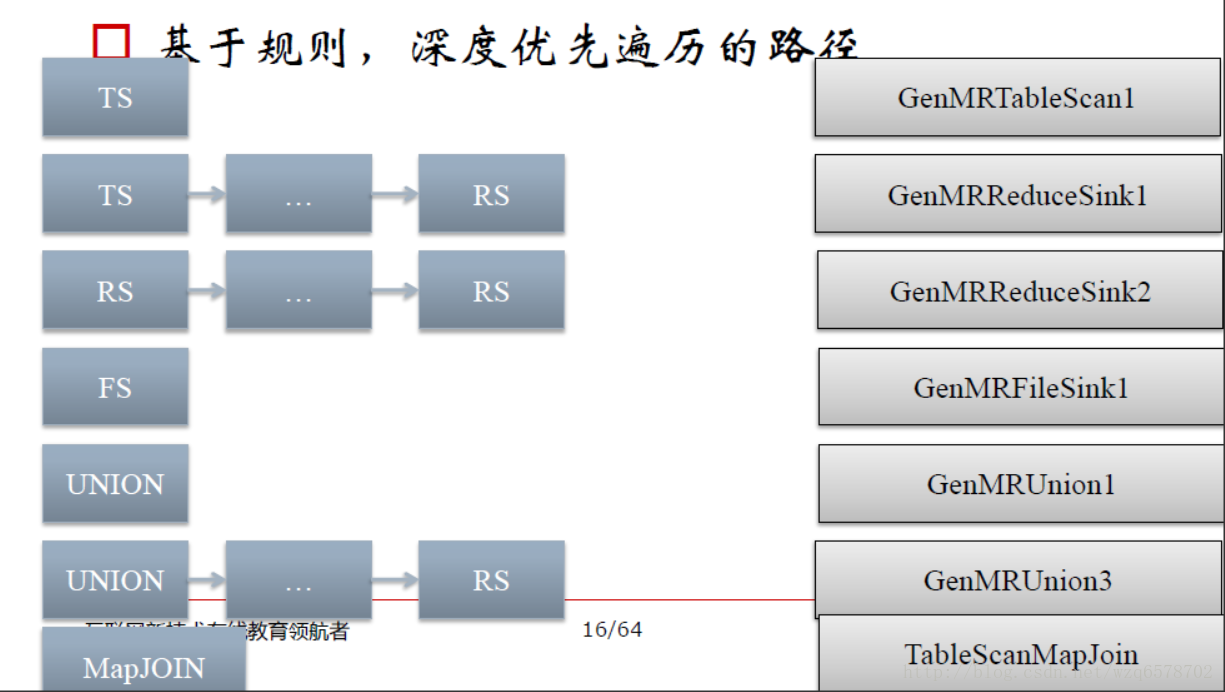
这个过程就是讲逻辑执行计划切分成物理执行计划。
如何切割逻辑执行计划?
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/GenMapRedUtils.java?line=405
1 | /** |
MR物理优化器
spark物理执行计划、tez物理执行计划、mr物理执行计划之后会有物理优化器,下列是一些优化器
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/optimizer/physical/PhysicalOptimizer.java?line=47
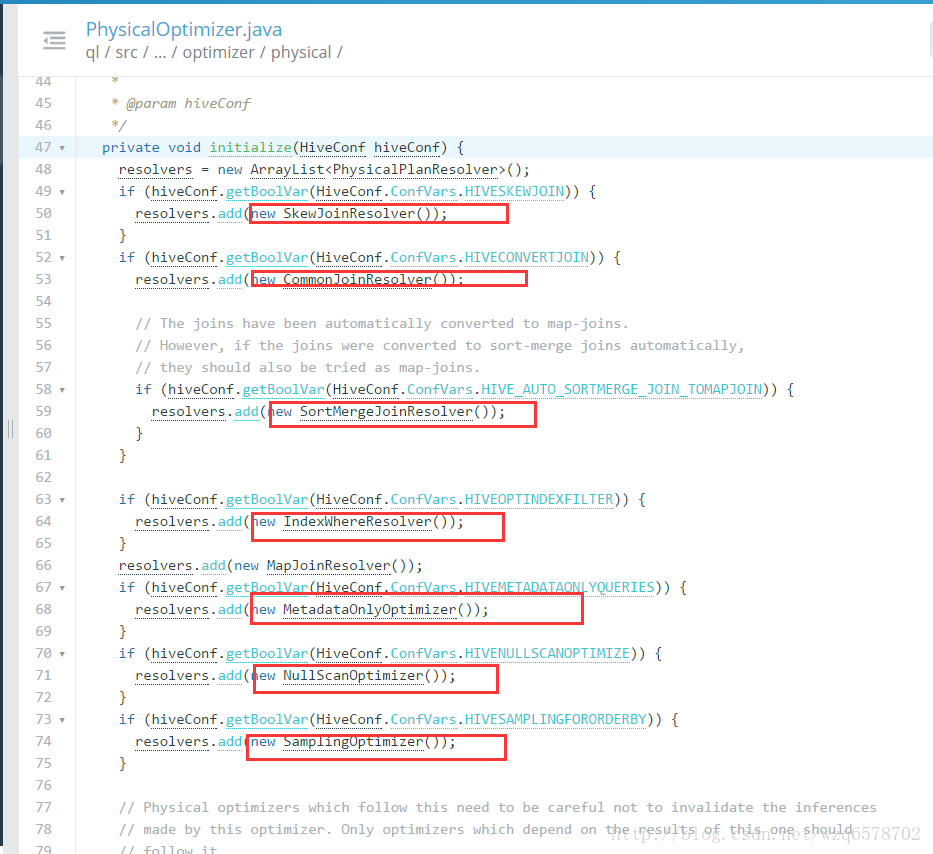
这些优化器是为mr专用的,而spark和tez是不用这些优化器的。
奇怪的是mr物理优化器的名字是PhysicalOptimizer,而逻辑优化器就是Optimizer。
hive-on-MR vs hive-on-tez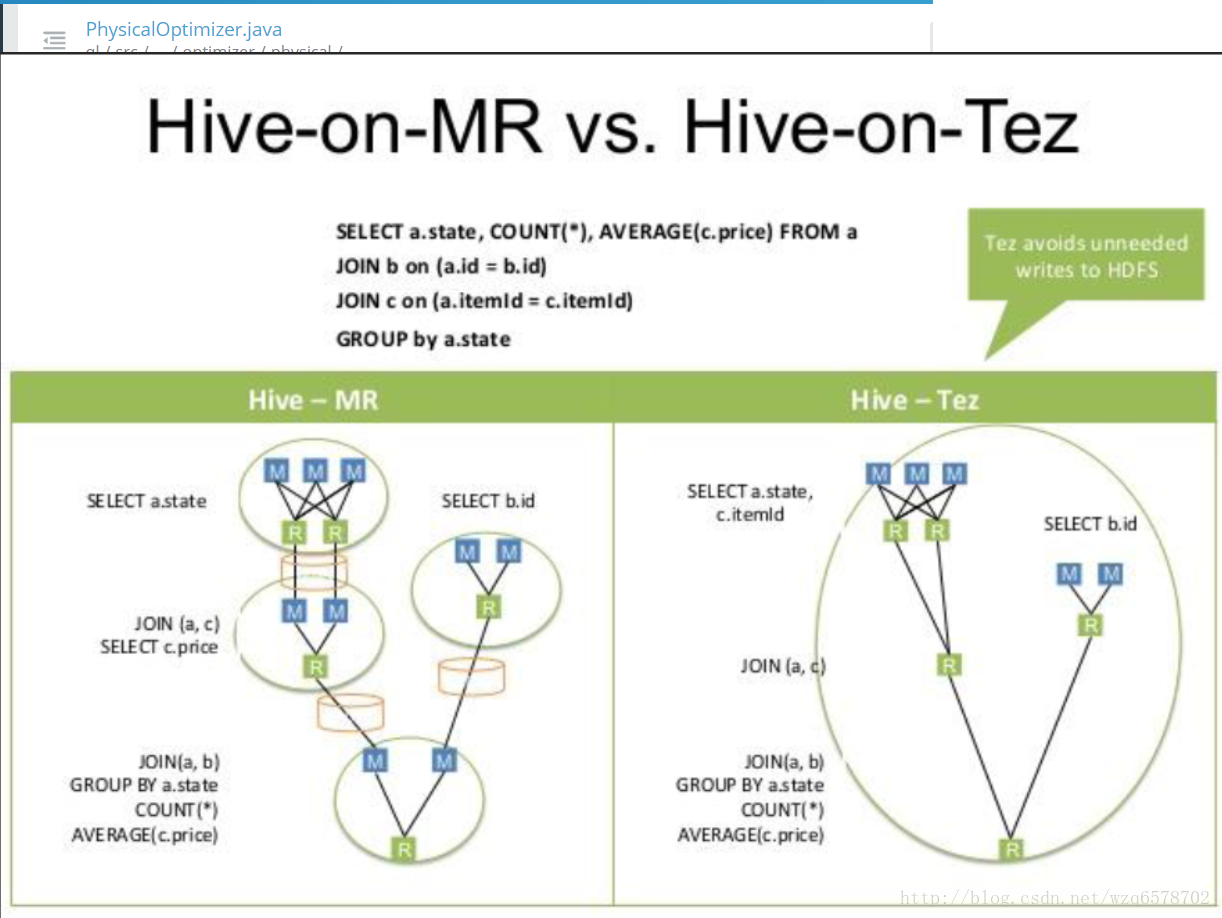
从图中可以看出,加入mr的方式中间有一些机器死掉了,但是他们计算的中间结果会写到磁盘,下一次会接着执行,数据不会丢失,但是tez的形式中间数据没有落盘,只要死掉数据就会有问题。这就是mr和tez的区别,mr更稳定一些,tez比较快。
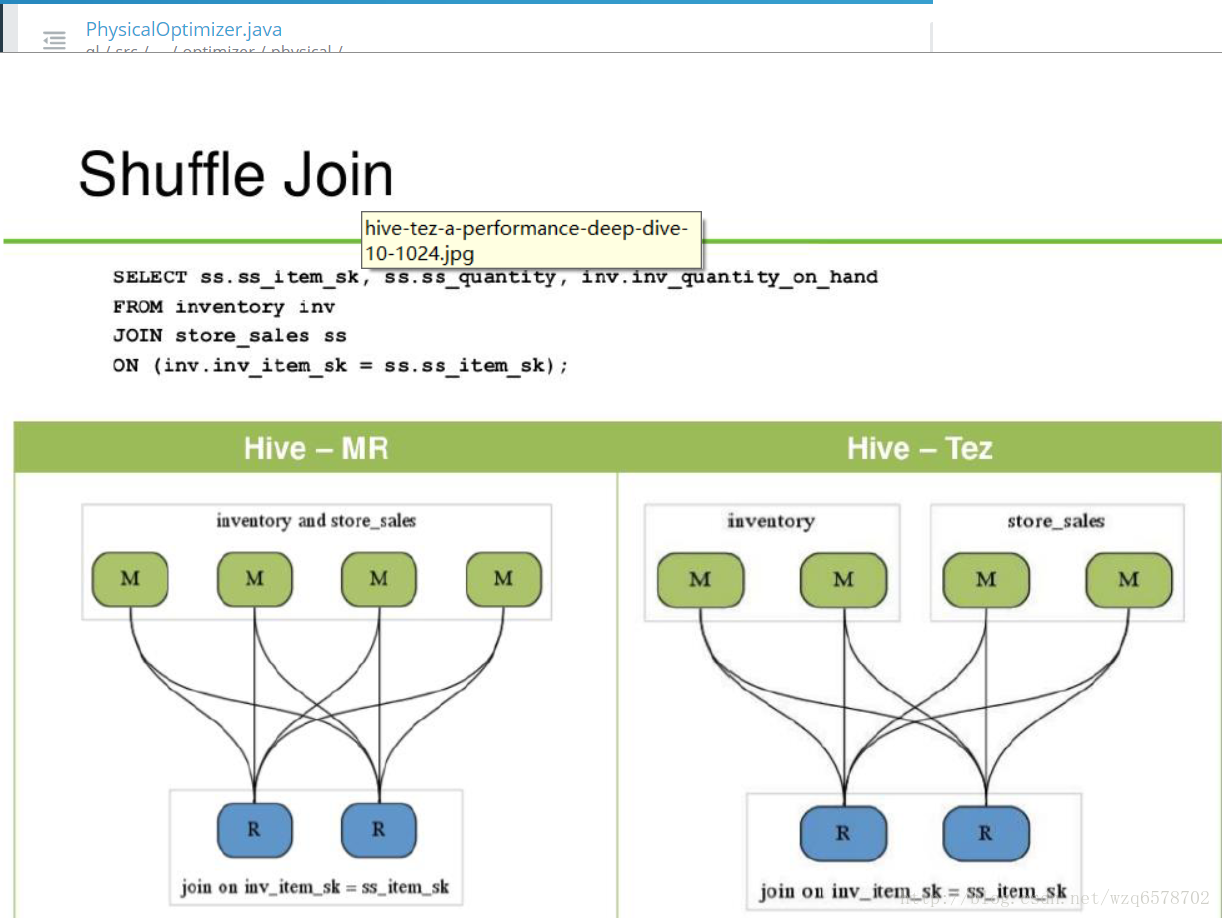
shuffle的区别
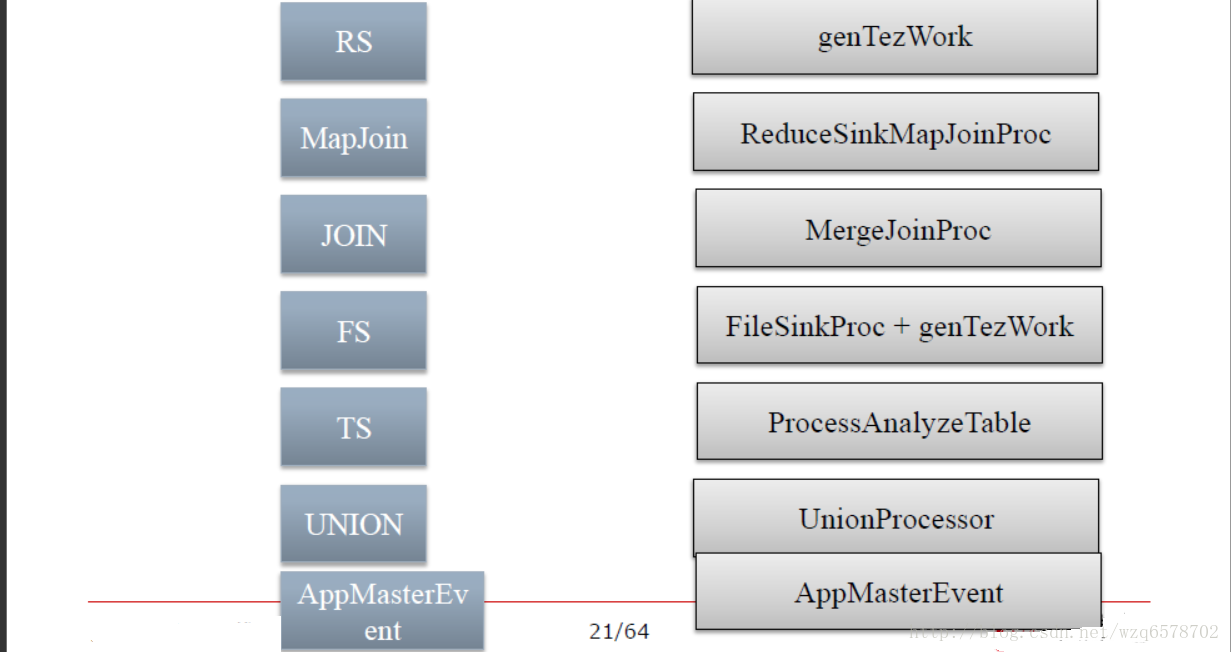
TezCompiler
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/parse/TezCompiler.java?line=457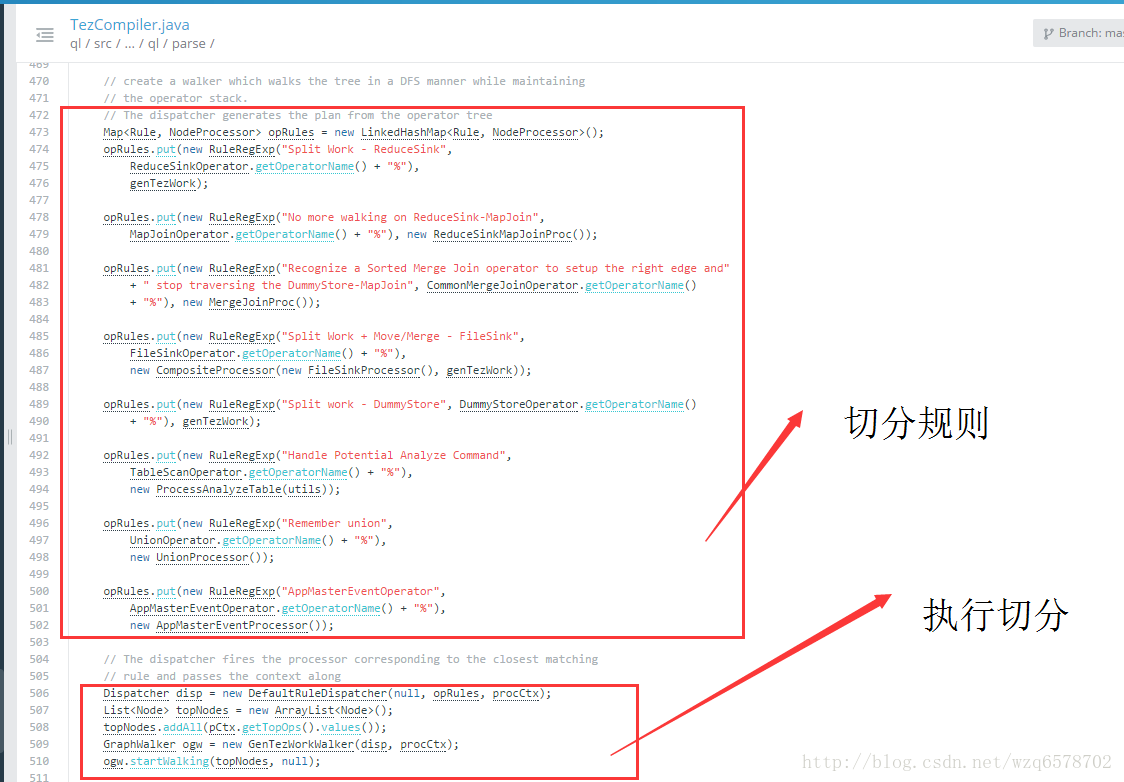
SparkCompiler
基本上和TezCompiler一致
代码注释上直接写着:
Cloned from TezCompiler
优化器和逻辑执行计划的切分在一起
生成Spark作业
https://issues.apache.org/jira/secure/attachment/12652517/Hive-on-Spark.pdf
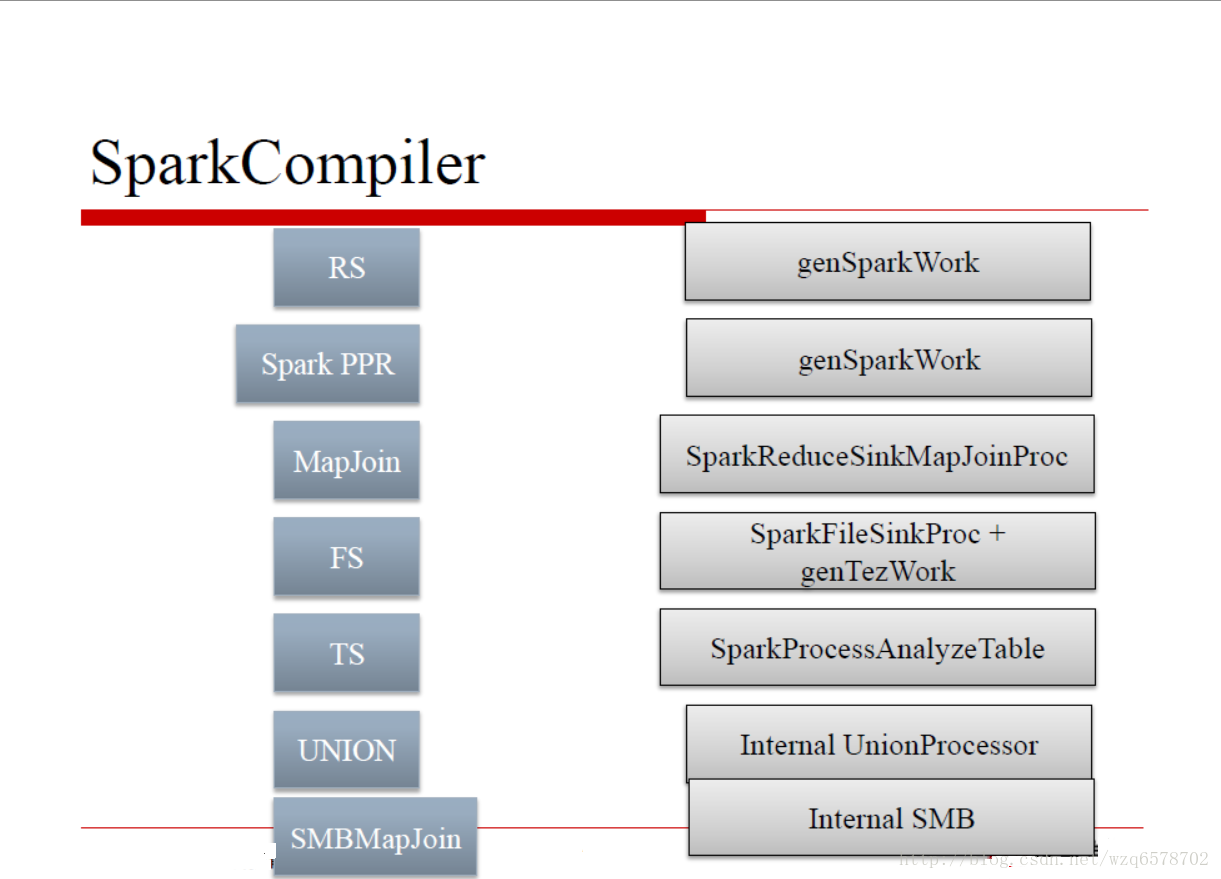
很有意思
Spark编译时直接拷贝了Tez代码
命名时加上了Spark前缀
进一步可见:Spark和Tez在执行机制上非常类似
基于路径规则优化总结
Optimizer会根据规则优化逻辑执行计划,并修改逻辑执行计划为优化后的逻辑执行计划
TaskCompiler(无论哪种)会根据规则来切分逻辑执行计划
Hive中对Operator图的修改基本上都是基于深度优先路径规则的
深度优先递规下降遍历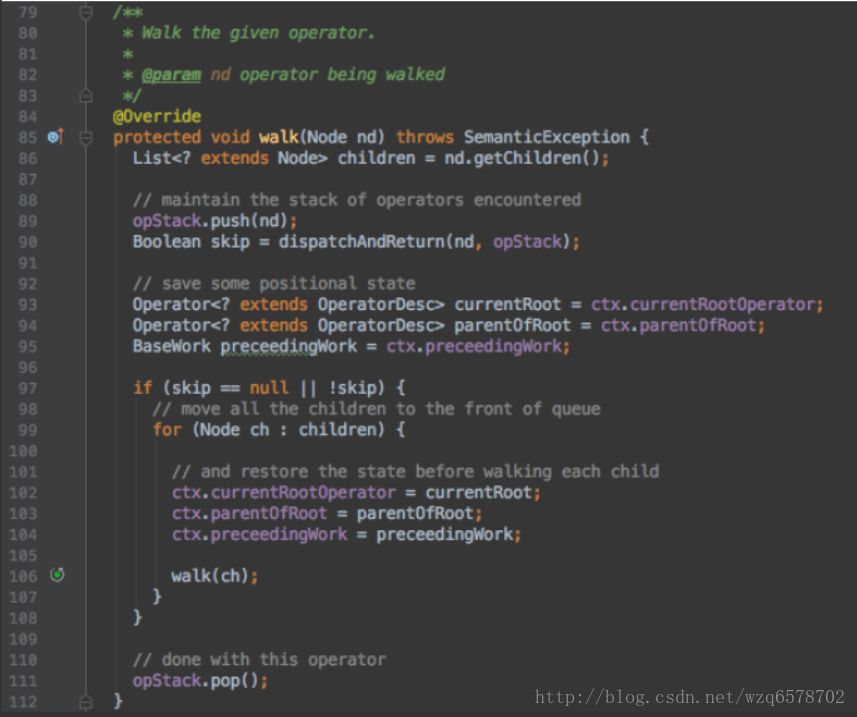
提交不同引擎的作业MR
提交不同引擎作业Spark
提交不同引擎的作业Tez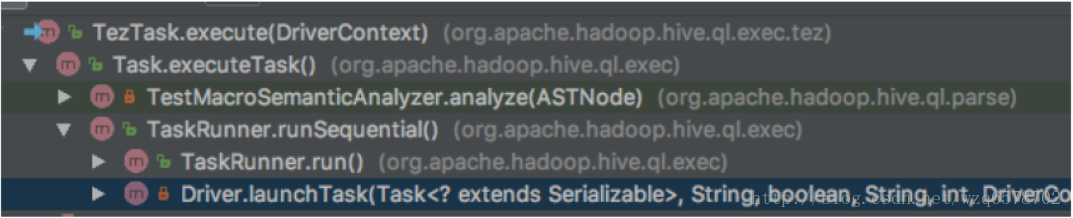
Driver的 launchTask方法:
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/Driver.java?line=2130
广度优先,并发提交
https://insight.io/github.com/apache/hive/blob/master/ql/src/java/org/apache/hadoop/hive/ql/Driver.java?line=1830