hive原理与源码分析-ACID及总结(八)
ACID是什么?
数据库事务的四个特征
Atomicity原子性:要么成功要么失败,不会残留一半的数据
Consisitency一致性:一旦操作完成,后续的操作可以看到操作的结果
Isolation隔离性:一个用户的未完成操作不会对其它用户产生影响
Durability持久性:一旦操作完成,操作将会持久化,不会受系统故障得影响
Hive ACID
Hive 0.13 以后的版本开始支持ACID
主要用于以下场景:
流式数据处理:如Flume, Storm和Kafka,数据进入即可见
不常变化的维表:如在维表中增加或者删除一个维度
数据订正:INSERT/UPDATE/DELETE
ACID限制
不支持BEGIN,COMMIT和ROLLBACK,只支持单条语句的ACID (Auto-Commit)
目前只支持Orc File Format
只支持分桶的表Bucketed
不支持从非ACID的会话读写ACID表(DbTxnManager)
只支持快照级别隔离
不兼容之前的ZooKeeperLockManager
虽然有很多限制,但是还是也有他的强项,比如流式API
Streaming APIs
https://cwiki.apache.org/confluence/display/Hive/Streaming+Data+Ingest (Hive 0.14)
https://cwiki.apache.org/confluence/display/Hive/HCatalog+Streaming+Mutation+API (Hive 2.0.0)
新的语法
INSERT INTO tbl VALUES(1, ‘fred’, …)
UPDATE tbl SET (x=5, …) WHERE …
DELETE FROM tbl WHERE …
支持分区表与非分区表(回忆PPR, PPD优化器)
一些限制
目前只支持ORCFile
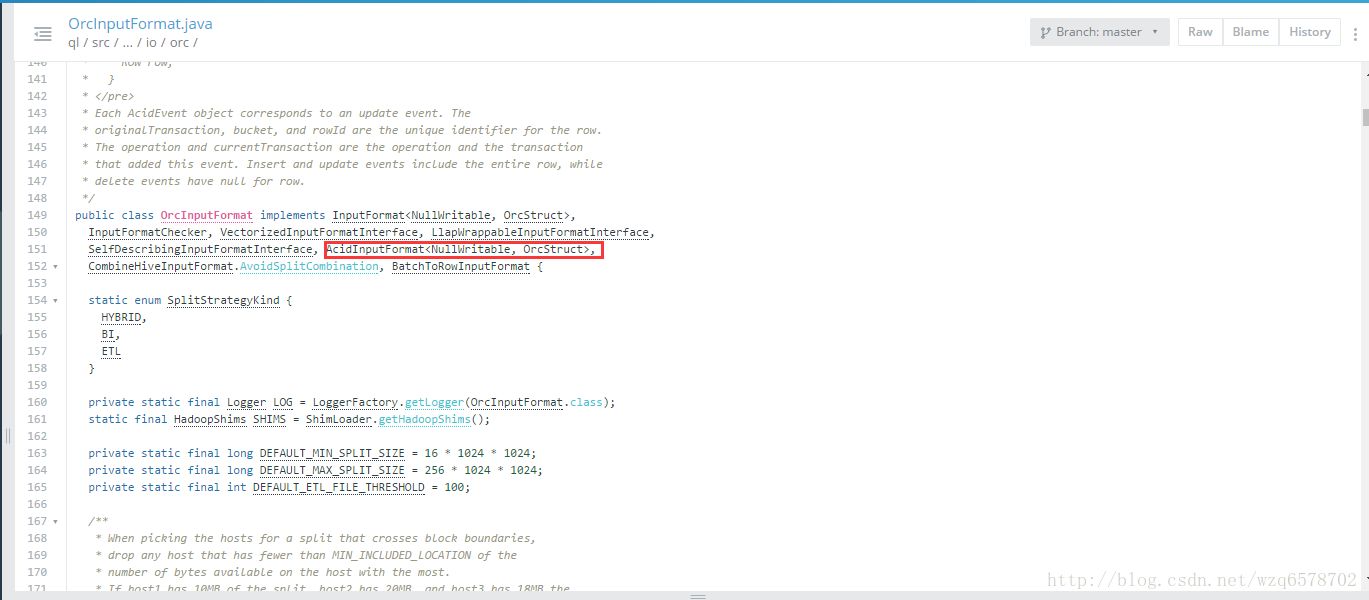
https://www.codatlas.com/github.com/apache/hive/master/ql/src/java/org/apache/hadoop/hive/ql/io/AcidInputFormat.java?line=108 源码告诉你为什么
要支持文件的事物,除了os提供之外,就是hive自己实现,比如:OrcInputFormat
表必须是Bucket表
可以只有一个Bucket,但性能会比单机还差
表上必须有transactional=true的标记
TBLPROPERTIES(‘transactional’ =‘true)
ACID设计
HDFS是一个Write-once, Read-many-times的文件系统,不支持文件修改(In-place Update)
把操作变成增量文件(Delta Files)
在读取的时间,合并增量文件(Stitched Together)
写的时候需要全局唯一的事务ID
由MetaStore生成
读的时候只读已经提交过的结果
快照一致性、无锁
查询开始时候向查询提供一份快照
Bucket和Partition的重要区别
Bucket是一个文件
Partition是一组文件
事务ACID必须基于Bucket + OrcFile
从理论上,以后可以支持多种文件的事务,但目前还不支持
文件合并
读的时候对原始文件和增量文件进行合并
ACID增量在HDFS上的存储
分区路径(Storage Descriptor)保持不变
$warehouse/$db/$tbl/$part
事务生成的bucket文件
基础文件Base Files: $part/base_$tid/bucket_*
增量文件Delta Files: $part/delta_$tid_$tid/bucket_*
InputFormat/OutputFormat
AcidInputFormat / AcidOutputFormat
全局唯一键事务、Bucket、行
AcidReader支持事务的版本号
目前只有Orc支持
文件分发
对于MapReduce读取文件(TableScan只在Map)
读取Splits同时读取Delta
Key Ranges
Indexes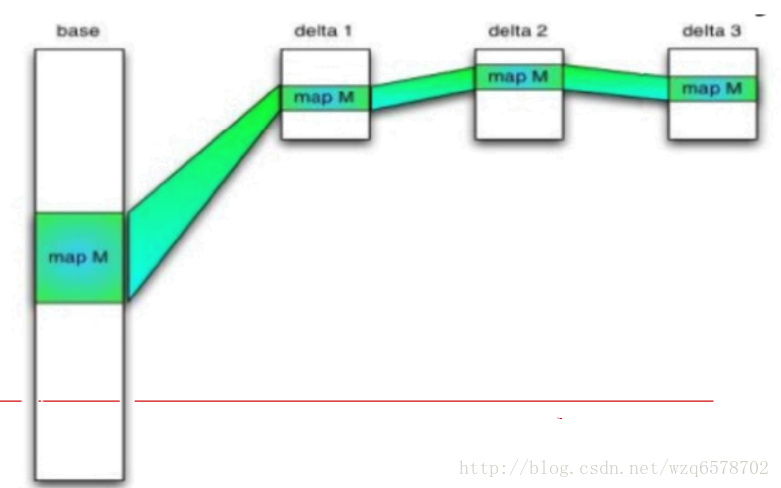
Delta会读到内存,有益处的风险,Delta一般 不会超过10个。
事务管理器Transaction Manager
Hive 0.14以前有两种表级的事务管理器,DML来了,表锁住,查询暂停,两种实现
In Memory – Not Durable 即放在内存里边,断电丢失
Zoo Keeper – 额外组件的安装,配置复杂
锁必须与事务相结合,事务提交时释放锁
MetaStore可以做ACID,因为MetaStore底层是关系型数据库中心结点
使用MetaStore DB(MySQL)生成全局唯一递增的事务Id
事务模型Transaction Model
互联网新技术在线教育领航者
事务模型Transaction Model
Hive 0.14开始,事务auto-commit,语句级
不支持BEGIN/COMMIT/ROLLBACK
快照隔离
整个查询执行期间,数据是一致的
SHOW TRANSACTIONS语句
锁模型Locking Model
三种类型的锁
Shared
Semi-Shared (能与Shared共存,不能与Semi-Shared共存)
Exclusive
不同操作需要不同类型的锁
SELECT, INSERT – shared
UPDATE, DELETE – semi-shared
DROP, INSERT OVERWRITE - exclusive
Compactor
每一个Transaction(或者Streaming中的一个Batch)创建一个增量文件(Delta File)
想象一会,会有很多Delta File,回忆一下会对Namenode造成什么影响
需要一些方式去合并
Minor Compaction: 把很多delta合并成一个delta
Major Compaction: 把很多delta合并成Base
Minor Compaction
当有10个(可配置)以上的增量文件时
结果:1个Base + 1个Delta
Major Compaction
当Delta达到基表的10%文件大小(可配置)时运行
结果只有一个基表
Compactor如何执行?
MetaStore定期执行
不需要用户手工调度
ALTER TABLE COMPACT语句
无锁,可与Query/DML同时执行
在一边执行,然后原子性替换
SHOW COMPACTIONS
流式写入
数据流式地流入Hive
没有流式功能的话,通常需要小时调度
hive.hcatlog.streaming接口
用户实时看到数据,可实时查询
Flume/Storm/Kafka
参考代码及实现
https://issues.apache.org/jira/browse/HIVE-5317
Hive再看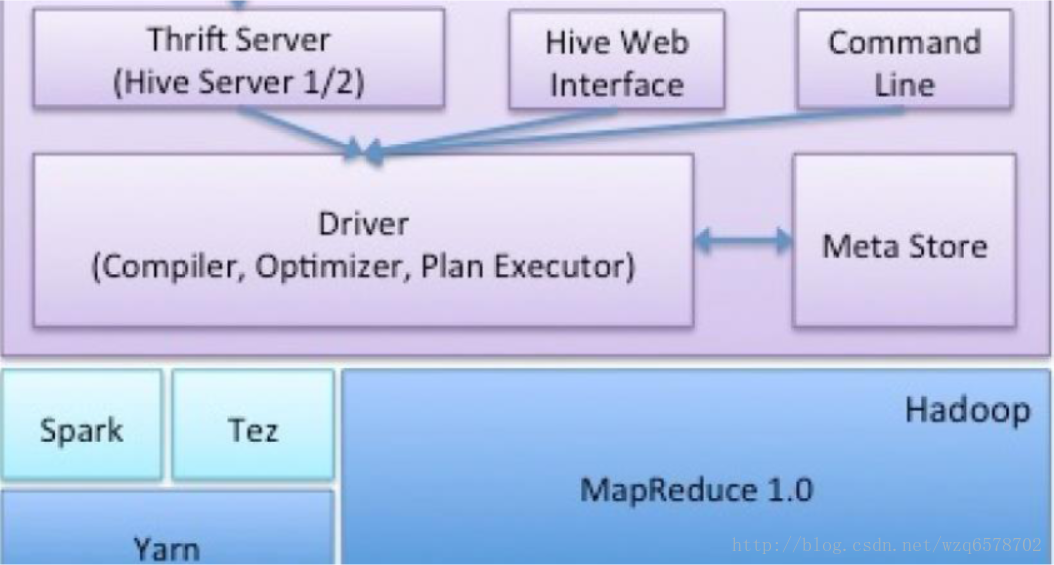
复习及总结
Hive是什么?
Driver做什么用的?
逻辑优化器?
物理优化器?
四种执行引擎?
查看执行计划?
JOIN/Group By倾斜怎么办?
HiveServer 2/ MetaStore/ LLAP
ACID
Hive Join优化
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+JoinOptimization
对抗倾斜
Hive CBO
https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
自定义优化器